一、分析需要爬取的网站
1.打开官方王者荣耀壁纸网站:
https://pvp.qq.com/web201605/wallpaper.shtml
2.快捷键F12,调出控制台进行抓包
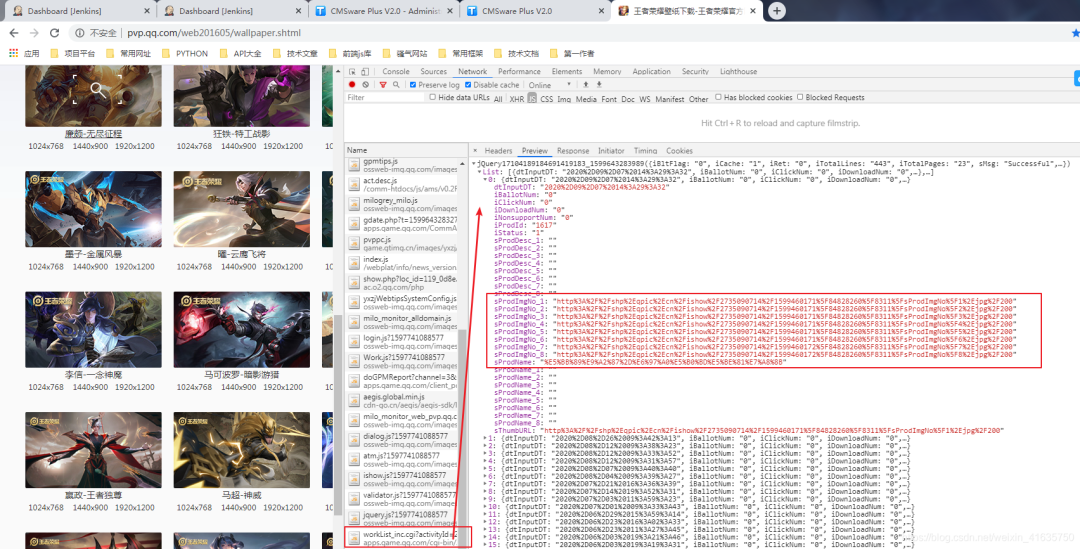
3.找到正确的链接并分析
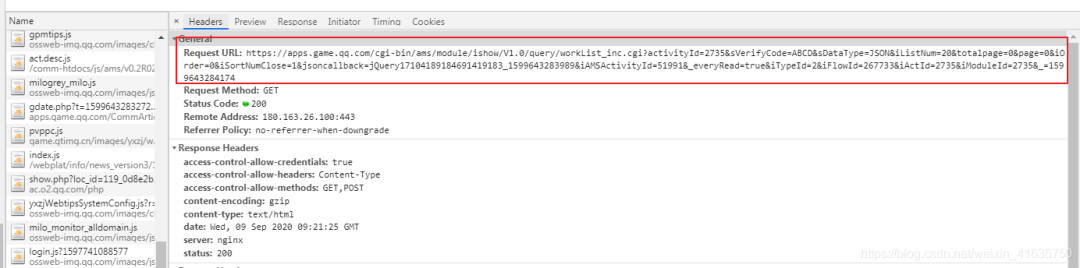 4.查看返回数据格式
4.查看返回数据格式
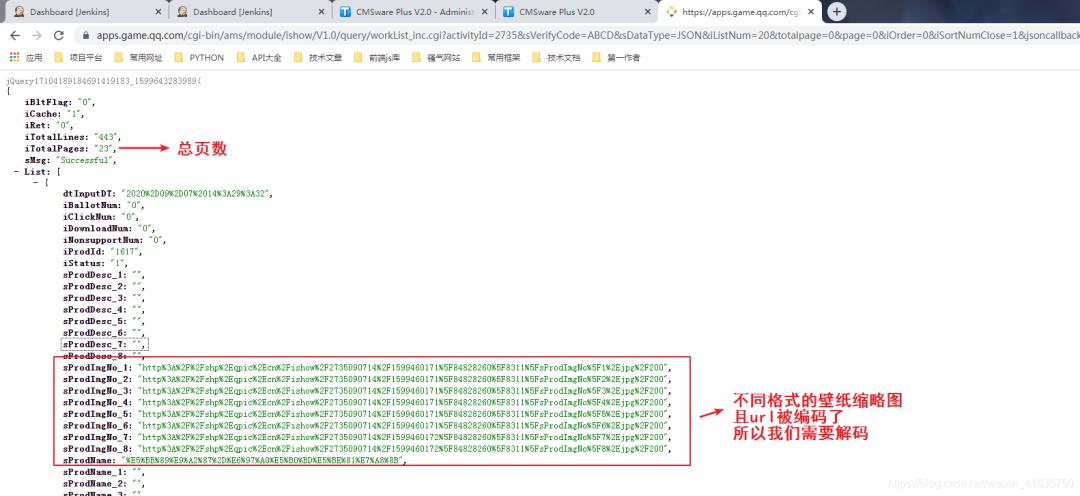 5.解析url链接
5.解析url链接
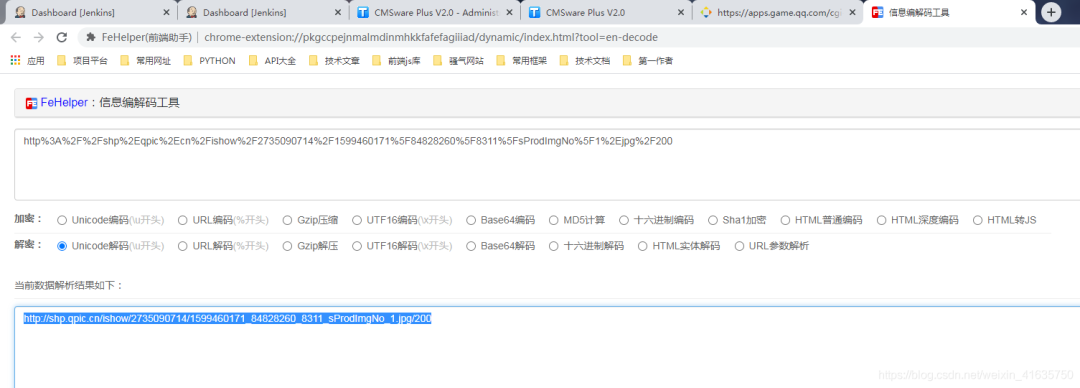 6.查看url内容是否是所需图片,发现其实是缩略图
6.查看url内容是否是所需图片,发现其实是缩略图
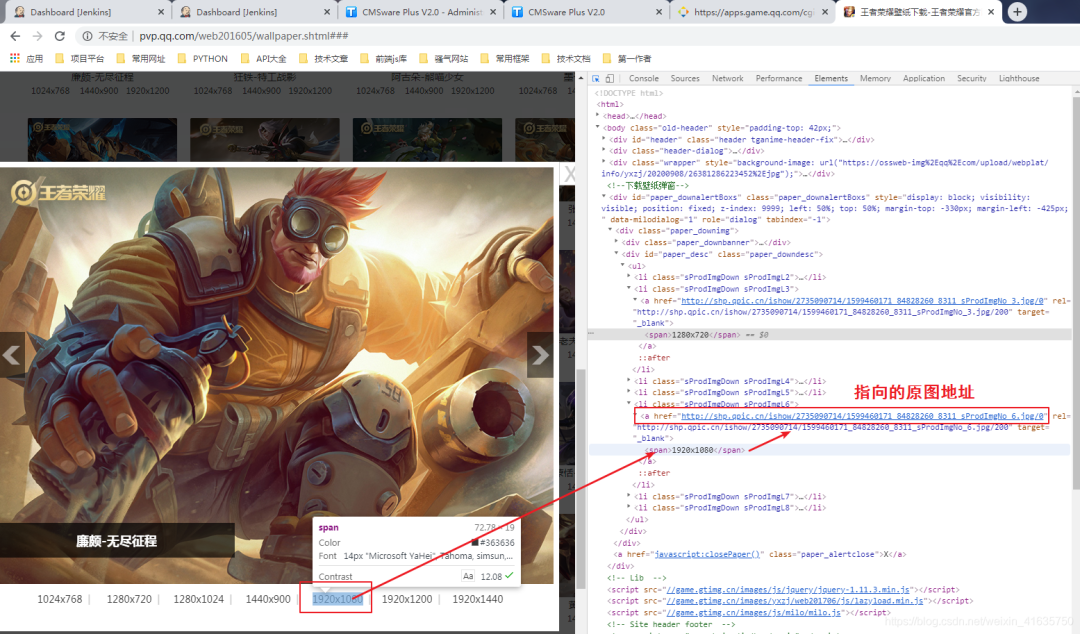
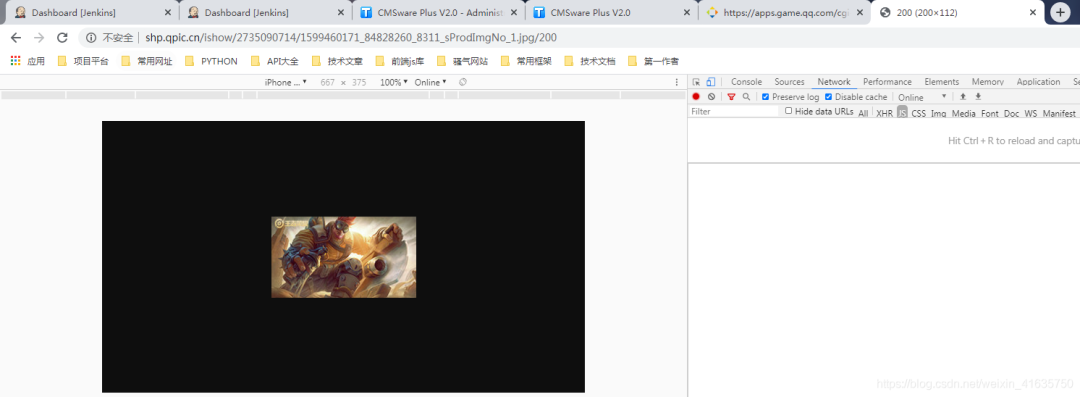 7.那就去分析网站,随便点开一张壁纸,查看指定格式的链接
7.那就去分析网站,随便点开一张壁纸,查看指定格式的链接
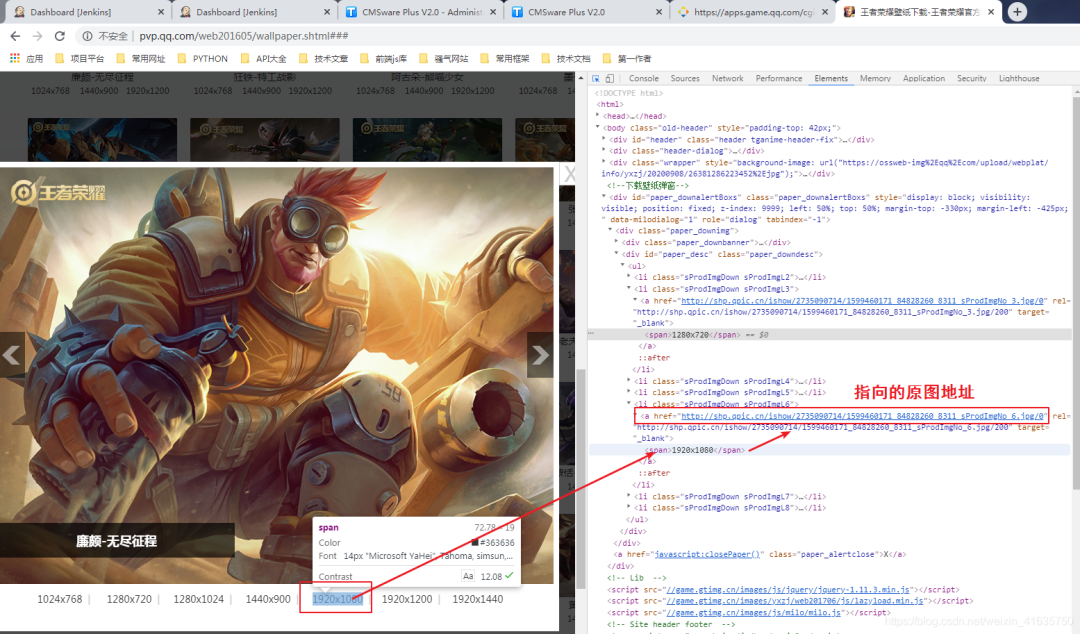 8.找到目标地址
8.找到目标地址
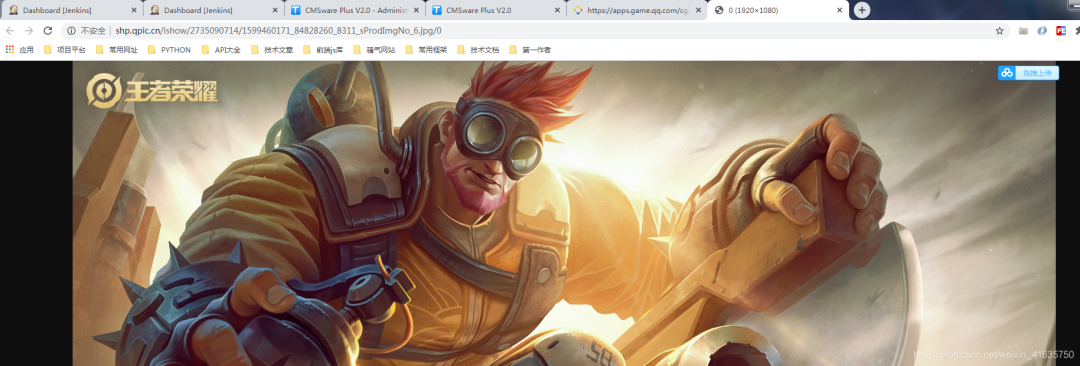 9.分析目标链接和缩略图的链接区别
9.分析目标链接和缩略图的链接区别
缩略图:
http://shp.qpic.cn/ishow/2735090714/1599460171\_84828260\_8311\_sProdImgNo\_6.jpg/200
{kind=link}
目标图:http://shp.qpic.cn/ishow/2735090714/1599460171\_84828260\_8311\_sProdImgNo\_6.jpg/0
{kind=link}
可以知道,将指定格式的缩略图地址后面200替换成0就是目标真是图片 1.至此,爬虫分析完成,爬虫完整代码如下
import os, time, requests, json, re
from retrying import retry
from urllib import parse
class HonorOfKings:
def __init__(self, save_path='./heros'):
self.save_path = save_path
self.time = str(time.time()).split('.')
self.url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=%s' % self.time[0]
def hello(self):
'''
This is a welcome speech
:return: self
'''
print("*" * 50)
print(' ' * 18 + '王者荣耀壁纸下载')
print(' ' * 5 + '作者: Felix Date: 2020-05-20 13:14')
print("*" * 50)
return self
def run(self):
'''
The program entry
'''
print('↓' * 20 + ' 格式选择: ' + '↓' * 20)
print('1.缩略图 2.1024x768 3.1280x720 4.1280x1024 5.1440x900 6.1920x1080 7.1920x1200 8.1920x1440')
size = input('请输入您想下载的格式序号,默认6:')
size = size if size and int(size) in [1,2,3,4,5,6,7,8] else 6
print('---下载开始...')
page = 0
offset = 0
total_response = self.request(self.url.format(page)).text
total_res = json.loads(total_response)
total_page = --int(total_res['iTotalPages'])
print('---总共 {} 页...' . format(total_page))
while True:
if offset > total_page:
break
url = self.url.format(offset)
response = self.request(url).text
result = json.loads(response)
now = 0
for item in result["List"]:
now += 1
hero_name = parse.unquote(item['sProdName']).split('-')[0]
hero_name = re.sub(r'[【】:.<>|·@#$%^&() ]', '', hero_name)
print('---正在下载第 {} 页 {} 英雄 进度{}/{}...' . format(offset, hero_name, now, len(result["List"])))
hero_url = parse.unquote(item['sProdImgNo_{}'.format(str(size))])
save_path = self.save_path + '/' + hero_name
save_name = save_path + '/' + hero_url.split('/')[-2]
if not os.path.exists(save_path):
os.makedirs(save_path)
if not os.path.exists(save_name):
with open(save_name, 'wb') as f:
response_content = self.request(hero_url.replace("/200", "/0")).content
f.write(response_content)
offset += 1
print('---下载完成...')
@retry(stop_max_attempt_number=3)
def request(self, url):
response = requests.get(url, timeout=10)
assert response.status_code == 200
return response
if __name__ == "__main__":
HonorOfKings().hello().run()
2.详细分析链接
- 前端发送的是jsonp请求,这种数据在python不好处理,因为不是标准的json格式
- 因为其前面JQuery1710418919222这个字符串,有这个前缀,必然请求链接中有相同的callback参数,将其删除即可
- 这个链接还有很多参数可以删除,大家可以自己尝试,这里不做过多说明
- 这个请求链接中最重要的一个参数为页码数,也就是page这个参数:iListNum=20&totalpage=0&page={}
- 上面的三个参数是可用的,一个是20,指每页的数量,page抓包发现是从0开始的,这个需要注意一下,因为下面代码需要将总页数减1
self.url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={}&iOrder=0&iSortNumClose=1&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=%s' % self.time[0]
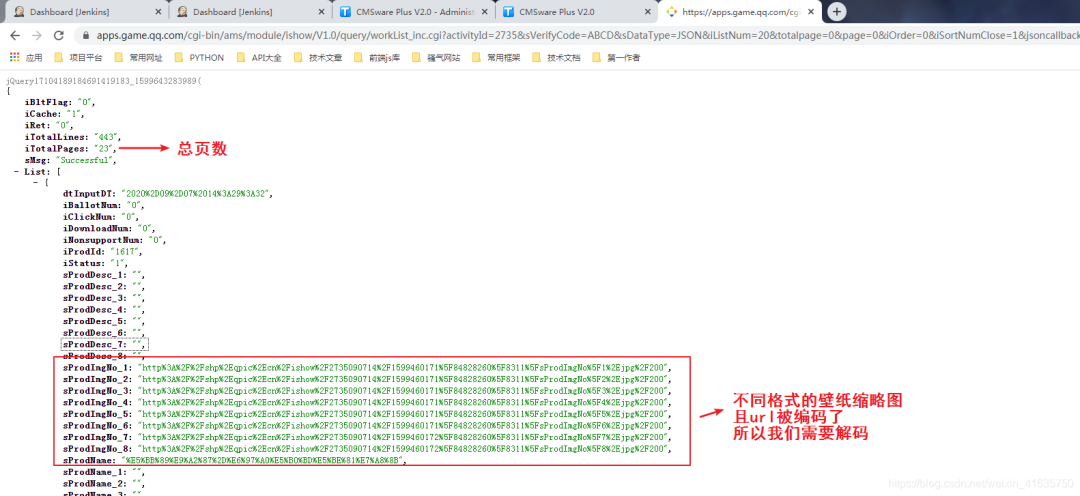
3.格式选择
- ·开始运行时,让你选择想下载格式的序号,为什么是8个格式呢,看原网页就知道了,8种不同分辨率的
- ·看上面的图片,缩略图链接有1-8,对应了8中分辨率的缩略图,那么原图必然也是8种
- ·这里我默认1920*1080的,一般电脑用这个分辨率的都可以
- ·其中1的原图,你自己试下,其实也是一个缩略图,所以一般下载选择2-8
print('↓' * 20 + ' 格式选择: ' + '↓' * 20)
print('1.缩略图 2.1024x768 3.1280x720 4.1280x1024 5.1440x900 6.1920x1080 7.1920x1200 8.1920x1440')
size = input('请输入您想下载的格式序号,默认6:')
size = size if size and int(size) in [1,2,3,4,5,6,7,8] else 6
 4.下载代码分析
4.下载代码分析
- 第一次请求主要是为了获取总页数,但是请求是从0开始为第一页,所以需要减去1
- while true中就是开始从0循环去请求地址,先找到缩略图地址,然后将缩略图的地址链接200替换成0就是目标图片地址了
- 如果名字中有特殊字符,就将其用正则去除,不然可能会影响路径的查找
print('---下载开始...')
page = 0
offset = 0
total_response = self.request(self.url.format(page)).text
total_res = json.loads(total_response)
total_page = --int(total_res['iTotalPages'])
print('---总共 {} 页...' . format(total_page))
while True:
if offset > total_page:
break
url = self.url.format(offset)
response = self.request(url).text
result = json.loads(response)
now = 0
for item in result["List"]:
now += 1
hero_name = parse.unquote(item['sProdName']).split('-')[0]
hero_name = re.sub(r'[【】:.<>|·@#$%^&() ]', '', hero_name)
print('---正在下载第 {} 页 {} 英雄 进度{}/{}...' . format(offset, hero_name, now, len(result["List"])))
hero_url = parse.unquote(item['sProdImgNo_{}'.format(str(size))])
save_path = self.save_path + '/' + hero_name
save_name = save_path + '/' + hero_url.split('/')[-2]
if not os.path.exists(save_path):
os.makedirs(save_path)
if not os.path.exists(save_name):
with open(save_name, 'wb') as f:
response_content = self.request(hero_url.replace("/200", "/0")).content
f.write(response_content)
offset += 1
print('---下载完成...')
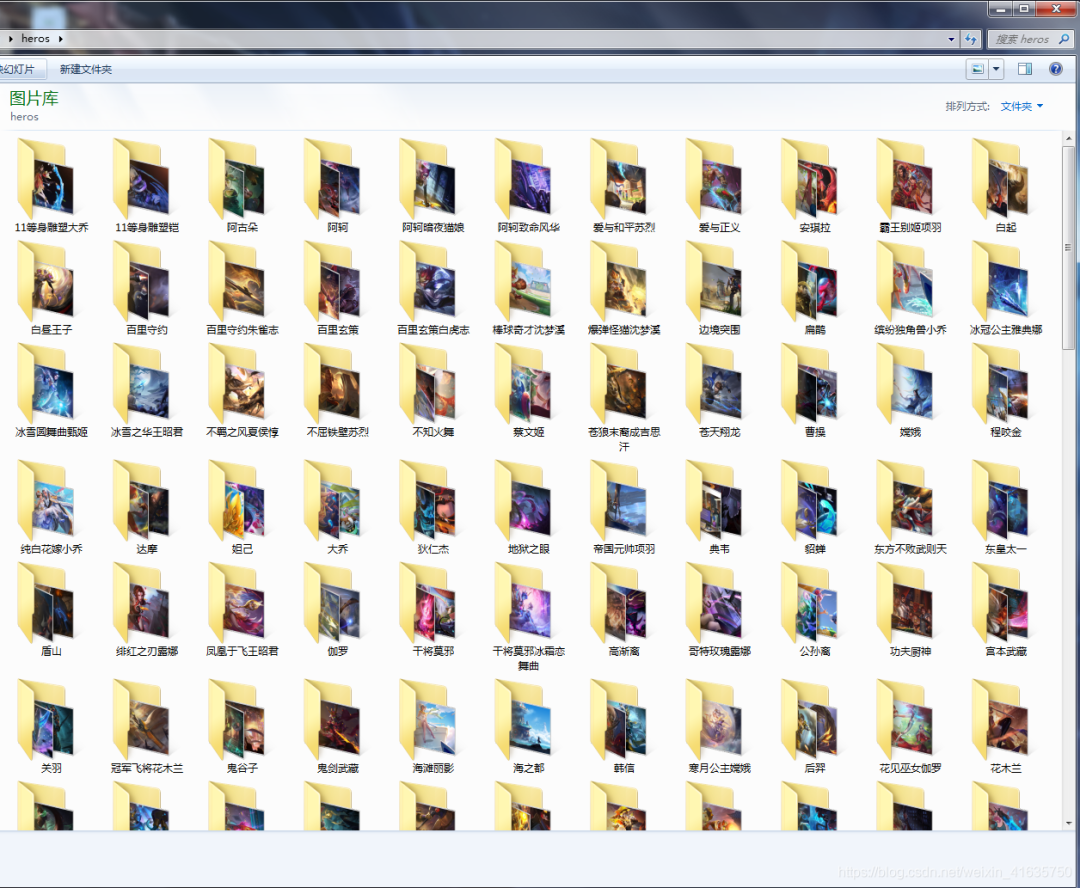
5·爬虫运行的结果,相同名字的放在同一个文件夹下
2 条评论
-
 xinao017 LV 7 @ 2024-2-1 15:45:24
xinao017 LV 7 @ 2024-2-1 15:45:24#include<bits/stdc++.h> using namespace std; const int N = 1e4+10; int a[1000]={}; int main(){ int n,m; cin>>n>>m; int cnt=n,s=1; while(cnt){ for(int i=1;i<=m;i++){ while(a[s]!=0){ s++; if(s>n){ s=1; } } if(i==m){ a[s]=1; cout<<s<<" "; } s++; if(s>n){ s=1; } } cnt--; } return 0; } -
@ 2024-1-6 19:42:33
- 1